Verification progress tracking with obsidian

The Ultimate Question of Life, the Universe, and Everything
The main question in verification is “Are we done yet?” And before you mutter something about covergroups and code coverage and turn back to funny cat videos, let me stop you. Functional and code coverages are only a part of the answer. Just looking at the coverage report one can’t draw any conclusion about coverage of requirements.
And how does one cover a requirement? By creating testcases, covergroups and checkers related to this requirement.
When the requirements have been covered? When all the related testcases pass, covergroups have been closed and checkers have executed.
How does one track the progress from having a heap of requirements and nothing else to covered requirements? That’s when things get murky
Verification progress tracking
There are a lot of ways to track verification progress, from filing an Excel document by hand to solutions like vManager, that promise to take care of your every need (whether it holds to the promise, is another question). I’m going to let these sleeping dogs lie and instead propose a concept of a new solution. For no other reason than because I can.
My solution:
- Is free.
- Is easy to set up.
- Allows collaboration.
- Allows scripting extensions.
- Is not a pain in the ass to use (I hope).
- Is cross-platform.
- Was created in two evenings, so don’t expect miracles.
Obsidian tracking
Overview
Lo and behold, Obsidian, a Markdown note-taking app turned into something it’s not supposed to be. Let us start with the dessert and then proceed to the implementation.
To have an example, let’s set up a verification plan for a cat. Yes, for a cat.
Below is a VPTD, Verification Progress Tracking Document, the primary point of our interest. It is centred around requirements and provides information about their coverage. 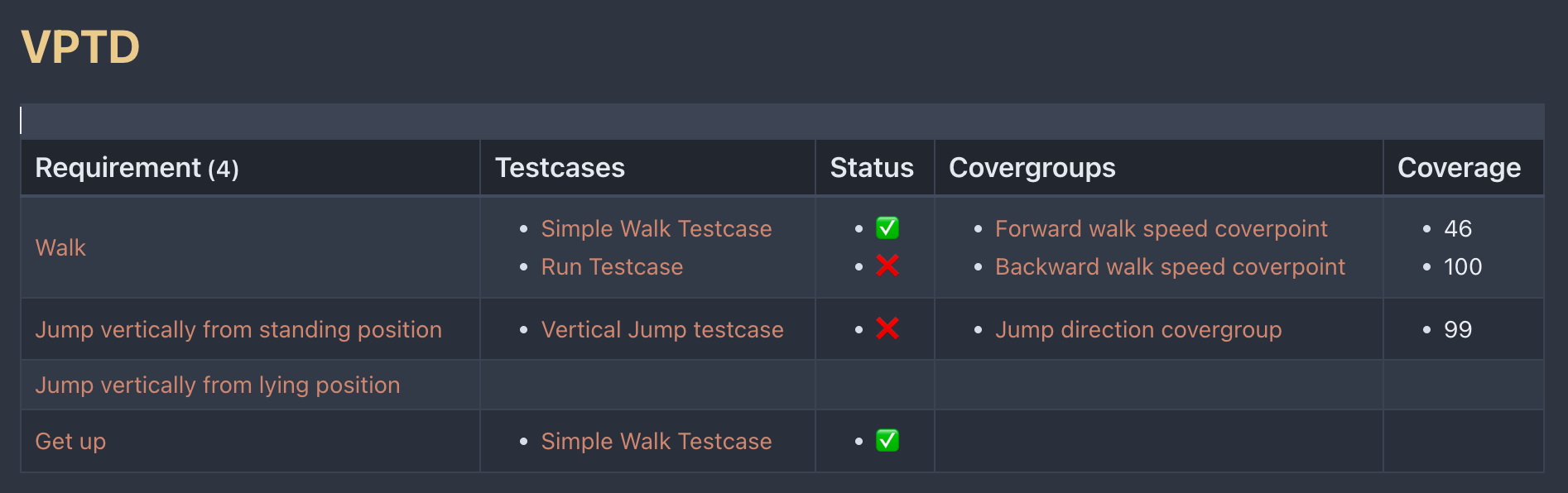 It shows all the requirements for the cat, and for each requirement, it shows associated testcases with a status and covergroups with a coverage percentage. Everything in red font here is a clickable link to another page. The table is generated automatically. Requirement pages have links to related testcases and covergroups. Testcases and covergroups pages have status information.
It shows all the requirements for the cat, and for each requirement, it shows associated testcases with a status and covergroups with a coverage percentage. Everything in red font here is a clickable link to another page. The table is generated automatically. Requirement pages have links to related testcases and covergroups. Testcases and covergroups pages have status information.
One can easily see that no requirement is covered, that is, has a link to testcase, which all pass, and links to covergroups, which are all 100% covered. Moreover, two requirements don’t have covergroups and one doesn’t even have testcases.
To simplify the identification of holes we have a dashboard with various issues. Each list and table is generated automatically. 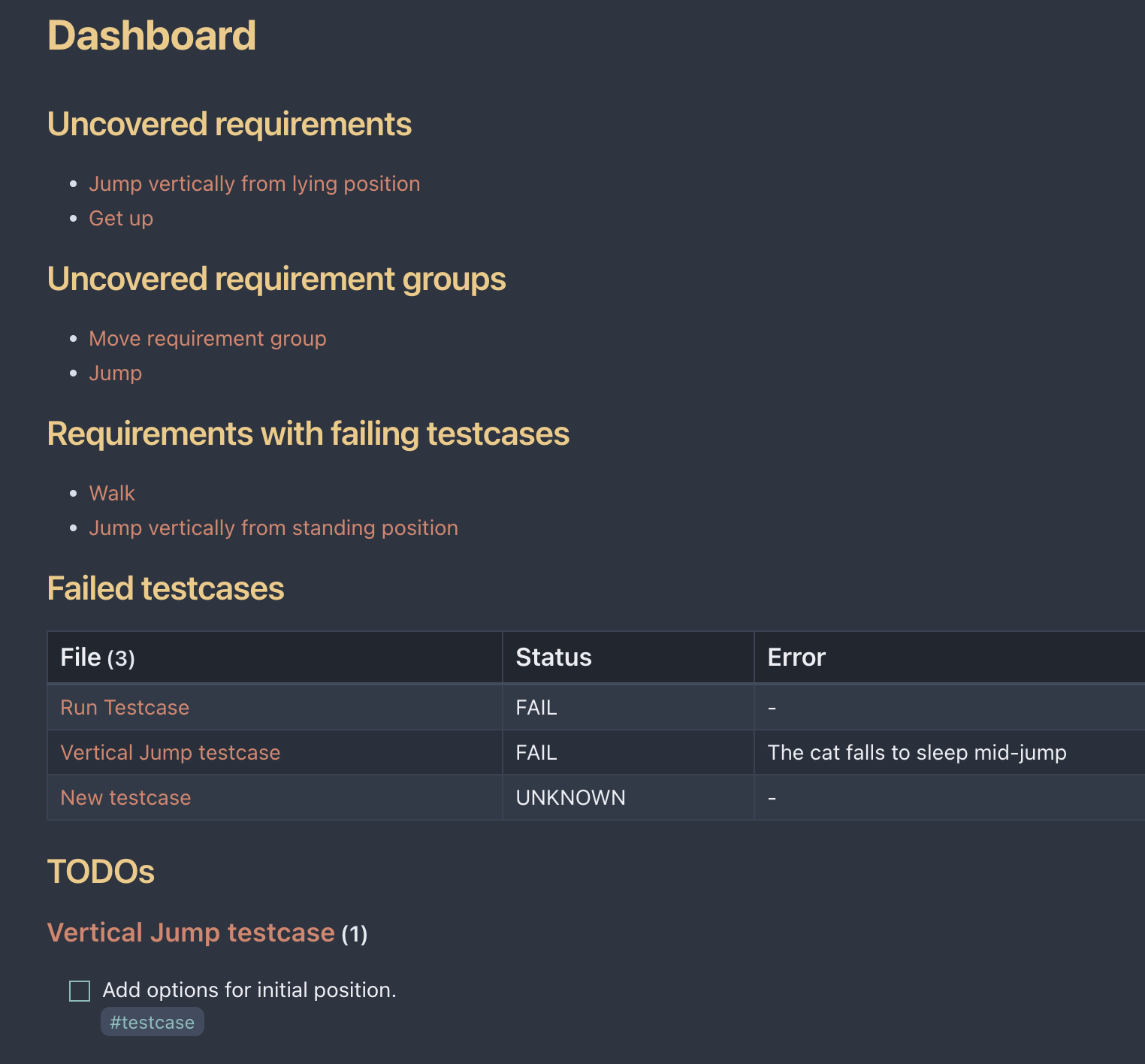 The first list provides a list of requirements with no linked testcase of a covergroup. The second list shows uncovered comples requirement. These are requirements that consist of other requirements and a covered by covering every child requirement. More on it later. The third list shows which requirements have linked testcases, but some of these testcases fail. The table shows the list of all failed testcases along with their respective errors. The final list aggregates all unfinished todos from all testcases.
The first list provides a list of requirements with no linked testcase of a covergroup. The second list shows uncovered comples requirement. These are requirements that consist of other requirements and a covered by covering every child requirement. More on it later. The third list shows which requirements have linked testcases, but some of these testcases fail. The table shows the list of all failed testcases along with their respective errors. The final list aggregates all unfinished todos from all testcases.
Implementation
Every page in Obsidian is a Markdown file stored on a hard drive. Keeping files locally on the one hand simplifies any external scripting, on the other hand, allows collaboration with shared folders, GIT and Dropbox-like cloud storage.
Requirements
Let’s take a look at the “Jump vertically from standing position” page.
## Covered by
### Testcases
- [[Vertical Jump testcase]]
### Covergroups
- [[Jump direction covergroup]]
#requirement It contains clickable links to a testcase and a covergroup.
Here’s how it renders: 
To simplify a page creation there are templates. Here’s the one for a requirement:
## Covered by
### Testcases
-
### Covergroups
-
#requirement To use it create a new page, hit Cmd+P (on Mac) and type “Insert template”.
Sometimes we have requirements that are too big and complex and have to be split into a number of smaller requirements. One such requirement from our example is Jump:
A cat should be able to jump: perform an explosive movement with rapid change of location in the direction in any combination of forward and upward.
Subrequirement:: [[Jump vertically from lying position]]
Subrequirement:: [[Jump vertically from standing position]]
#requirement_group I assign a different tag for such requirements because they have to be processed quite differently from their simplier counterparts.
Subrequirements are listed with the prefix Subrequirement ::. This is a Dataview inline field. We will use it to find complex requirements for which at least one subrequirement is not covered.
Testcases
Jumping to “Vertical Jump testcase” reveals the next file:
---
sv_name: vert_jump_test
Status: FAIL
Error: The cat falls to sleep mid-jump
---
## Description
Test the cat's jumping ability, from any position.
## Test steps
## TODO
- [ ] Add options for initial position.
#testcase Here’s something new. Three dashes denote the so-called YAML frontmatter, an arbitrary key-value collection. It will help us get information about testcases in an automated way. Note the to-do. It is the same one as on the Dashboard page. The field sv_name will help an external script to update this page with regression results.
Covergroups
Let’s take a look at “Walk speed covergroup”
---
cg_name: walk_speed_cg
cp_names: fw_speed_cp, bw_speed_cp
coverage: 15
---
## Coverpoints:
```dataview
list
from #coverpoint
where contains(this.cp_names, cp_name)
```
#covergroup Here again, we see YAML frontmatter. The cg_name field shows the covergroup name in the TB. cp_names serves the same purpose.
Below we see the dataview code block. Dataview is the Obsidian plugin that does all the magic of dynamically executing complex search queries and makes the whole concept possible. Its syntax is similar to SQL. In this case, we build a list by searching all pages with the “coverpoint” tag and preserve only those, whose cp_name field is contained in the covergroup’s field cp_names. This allows us to describe covergroups and their coverpoints on separate pages and insert the respective links into the page automatically. The Dataview query does not contain any page-specific information, so it can be put into the covergroup template.
Here’s the rendering of the page  The coverpoint page is very similar.
The coverpoint page is very similar.
---
cp_name: fw_speed_cp
coverage: 46
---
Belongs to the covergroup:
```dataview
list
from #covergroup
where contains(cp_names, this.cp_name)
```
#coverpointThe query is mirrored to show the parent covergroup.
Complex queries for dashboard and VPTD
Now let’s take a look at the Dataview queries that form the Dashboard and VPTD pages.
Here’s how we search for uncovered requirements.
```dataview
list
from #requirement and -"Templates"
where (!contains(file.outlinks.file.tags, "testcase")) or
(!contains(file.outlinks.file.tags, "covergroup") and !contains(file.outlinks.file.tags, "coverpoint"))
```First, we shall exclude the Templates folder with -"Templates". We’ve already seen the contains method, but what’s file.outlinks.file.tags?
fileis an implicit variable that keeps every file from the getterfrom;outlinksis the file’s property that contains all links to other files;- to get the linked file, we use the
fileproperty ofoutlinks; - finally,
tagsis a list of tags in the file.
To see the list of all implicit fields, check out the Dataview documentation
The task to find all uncovered requirement groups is much more complex. A requirement group can be composed of other requirement groups and simple requirements and we have to analyze a tree. I don’t think it can be solved with Dataview queries, but fortunatelly, Dataview allows us to write JavaScript code.
```dataviewjs
function is_uncovered(req_page) {
return (!req_page.file.outlinks.file.tags.includes("#testcase")) ||
(!req_page.file.outlinks.file.tags.includes("#covergroup") &&
!req_page.file.outlinks.file.tags.includes("#coverpoint"));
};
let req_groups = dv.array(dv.pages('#requirement_group and -"Templates"'));
let uncovered_reqs = new Set();
for (let top_req of req_groups) {
let pages = new Set();
let stack = [top_req];
while (stack.length > 0) {
let elem = stack.pop();
let subreqs = elem.Subrequirement;
for (let sr of dv.array(subreqs)) {
if (!sr)
continue;
let p = dv.page(sr.path);
if (p.file.tags.includes("#requirement")) {
pages.add(sr.path);
}
stack.push(p);
}
}
pages = dv.array(Array.from(pages)).map(p => dv.page(p));
if (pages.some(is_uncovered))
uncovered_reqs.add(top_req);
}
let links = dv.array(Array.from(uncovered_reqs)).map(p => p.file.link);
dv.list(links)
```The uncovered function checks the same condition as the preivous Dataview query, but uses a JS syntax. The code collects fringe requirements and if some of them are uncovered, adds the requirement group to the list.
To find the requirements with failing testcases, we need to access the Status field of the testcase page. Recall, that we listed all the fields in the YAML frontmatter, so that’s the implicit field we shall access now.
```dataview
list
from #requirement and -"Templates"
where contains(file.outlinks.file.frontmatter.Status, "FAIL")
```This is the query to build the table of all failed testcases together with their exact status and an error message.
```dataview
table Status as "Status", Error as "Error"
from #testcase and -"Templates"
where Status != "PASS"
```Since now we filter through the results of the from operator, we can just refer to the fields directly. No need to go through any implicit fields. Before we used Dataview to build only lists, but it can also build tables and todo lists. To make a table we write table instead of list and list the fields that we want to display as columns.
And here’s how to make a to-do list.
```dataview
task
from #testcase
where !completed
group by file.link
```By default Dataview just dumps all todos in one list. To understand which to-do item comes from which file, we use group by file.link.
And now we come to the final of the freak show. The VPTD table.
```dataview
table without id
file.link as Requirement,
filter(file.outlinks, (t) => contains(t.file.tags, "testcase")) as Testcases,
map(filter(file.outlinks, (t) => contains(t.file.tags, "testcase")).Status, (x) => choice(x = "PASS", "✅", "❌")) as Status,
filter(file.outlinks, (t) => contains(t.file.tags, "covergroup") or contains(t.file.tags, "coverpoint")) as Covergroups,
filter(file.outlinks, (t) => contains(t.file.tags, "covergroup") or contains(t.file.tags, "coverpoint")).coverage as Coverage
from #requirement and -"Templates"
```Let’s go line by line.
By default, Dataview puts the found files in the column named “File”. To rename it, first we remove it completely by adding without id, then we add this column anew.
table without id
file.link as Requirement,We’ve already seen how to get the list of linked testcases, but that time we filtered the requirements with absent testcases. However, to build the VPTD table, we need to put these testcases in a separate column. Note, that there is no where operator at all! Almost all lines of the query describe columns, and the from operator comes at the very end.
To extract links to testcases from the requirement we employ the built-in function filter, which, completely unsurprisingly, has two arguments: an array and a predicate.
filter(file.outlinks, (t) => contains(t.file.tags, "testcase")) as Testcases,To render lame PASS/FAIL into something more appealing, the next line maps the filter’s result into✅/❌:
map(filter(file.outlinks, (t) => contains(t.file.tags, "testcase")).Status, (x) => choice(x = "PASS", "✅", "❌")) as Status,Covergroups are retrieved in the same fashion as the testcases, but we allow a requirement to refer not only to the whole covergroup but also to a coverpoint.
filter(file.outlinks, (t) => contains(t.file.tags, "covergroup") or contains(t.file.tags, "coverpoint")) as CovergroupsTo retrieve the coverage percentage, we simply get the coverage property from the result of the previous line.
filter(file.outlinks, (t) => contains(t.file.tags, "covergroup") or contains(t.file.tags, "coverpoint")).coverage as CoverageNote, that our VPTD table does not contain requirement groups. I’m a bit recultant to tear down this neat query and write a heap of JS code instead and also I’m not sure that’s the information I want to see in this table. Anyway, the examples you’ve seen to far should be enough to tweak any of the queries or write your own.
What’s left overboard
I do not suggest any particular way to connect Obsidian with the regression running tool of choice. This is because the choice will dictate the connection and implementing a script to update a couple of text fields is not rocket science.
In the very beginning, I mentioned that requirement has to be covered by testcases, covergroups and checkers, but I made no mention of the checker in the Obsidian tracking description. This is because
- Checker coverage is not different from covergroups and you can add it yourself
- Not everyone tracks checker coverage, so it’s better to leave this confusing concept out. I will briefly explain what it is later.
Obsidian has a built-in visualiser of pages’ connection. It looks like this:  I couldn’t think of a good application for this feature, so I won’t describe it in detail.
I couldn’t think of a good application for this feature, so I won’t describe it in detail.
I did not mention DUT and TB documentations, but you actually can write them right here, in Obsidian. Markdown is a fine solution for this. The most severe drawback I see is that the tables in Markdown are terrible. Writing a simple table is okay, but complex tables with merged cells can be anything from painful to impossible.
How to use
- Install Obsidian.
- Clone the example project.
Bonus: checker coverage
Since I’ve mentioned it before, I have to explain what it is and why I think it’s important.
Checker coverage has two bins: checker pass and checker fail. The former is mandatory if the checker is active. The latter should be used only if there’s an error injection scenario that triggers the respective error.
The pass coverage shows that the checker has been executed at least once. It’s a bit awkward to write a checker and then forget to call it, right? The fail coverage shows that the error injection scenario really injects the error. How to implement coverage for every checker and not go mad is a story for another time.
Conclusion
Born as a “what if” idea for a bored mind, the Obsidian verification tracker turned out to be not as ridiculous as it sounds. It offers basic features to track the verification progress and identify issues in the process. It’s hard to say how it will fare in a real project with one, two, ten, or twenty engineers, but it looks feasible enough to try it at least in home projects. At the very least, I hope you’ve appreciated the versatility of Obsidian, a wonderful piece of software. It deserves it.
